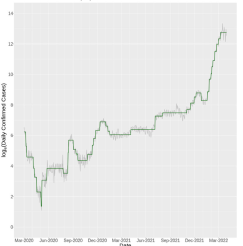
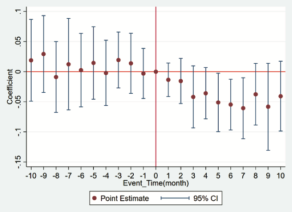
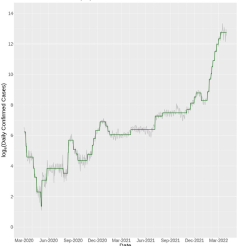
전례없는 감염병 확산은 향후 초래될 위협에 대한 예방책을 강구하는 것이 필요함을 강조한다. 본 연구에서 제안된 방법 (WTSM)은 대규모 감염병 발생 시 도시인구의 이동성 변화에 대한 패턴을 도출함으로써 도시의 기능 및 지역단위로 효과적인 정책 구상을 위해 활용 될 수 있을 것 이다. WTSM의 방법론적 함의는 다음과 같다. 일반적으로 공간 시계열 데이터는 다차원 속성을 지니고 있으며, 널리 쓰이는 Dynamic Time Warping (DTW)은 다른 길이의 stream 유사도를 측정할 수 있으나 상당한 계산복잡도가 수반되고 (O(m*n)), Symbolic Aggregate approXimation (SAX)은 DTW에 비해 계산이 빠르지만 각 구성요소를 알파벳화하는 과정에서 정보의 손실 및 왜곡을 발생시킨다. 이러한 단점을 극복하고자 본 연구에서는 효율적이고, 질적으로 높은 공간시계열 분석방법을 제안하여 이를 뉴욕의 코로나 기간 동안의 택시 데이터에 적용하였다. 클러스터링결과, 공통적으로 코로나 초기에 상당한 이동량 저하가 발생했음을 발견하였다. 뉴욕은 2020년도 12월의 첫 백신 이후, 일반 공중에게 확대됨에 따라 이동성이 점차 회복됨을 보였고, Bronx, Brooklyn, Downtown Manhattan 지역이 타 지역에 비해 회복탄성이 높은 것을 확인했다. 그러나, 시계열상으로 백신과 이동성 회복에 딜레이가 존재하는 것으로 보아, 백신도입이 즉각적인 이동회복으로는 이어지지 않았으며, 정부 및 사회의 노력 (예: 사회적 거리두기, 마스크, 백신접종 증대 등)을 통해 확진자 증가가 주는 충격 (effect of COVID-19 upsurge)은 지속되지 못하며, 변동하는 이동량 (daily fluctuating volumes)을 참고했을 때 뉴욕시민의 일상이 이동성에 큰 영향력을 발휘함을 발견했다.